
Installation Options
Eclipse supports multiple deployment models to accommodate varying institutional requirements, infrastructure capabilities, and jurisdictional regulations - it can be packaged and installed in many ways and is not prescriptive on the runtime architecture. It is built as a cloud-native architecture from the ground up, but with the advantage that most of the benefits of cloud native can be achieved even in on-premise deployments. The benefits of this cloud-native architecture are as follows:
-
📦 Containerization ensures portability
Apps run the same across dev, test, and prod — no more “works on my machine” issues. -
🔄 Immutable infrastructure improves stability
Systems are redeployed rather than modified, reducing drift and improving consistency. -
🔧 Microservices promote modularity
Break systems into independent components that can evolve separately. -
🧪 Continuous delivery enables fast, safe releases
Built-in support for CI/CD pipelines accelerates time-to-market while improving quality. -
📈 Auto-scaling & horizontal growth
Architected from the start to handle variable loads, even if scale is manual in a private DC. -
🛠 Declarative configuration (e.g. YAML, Helm)
Infrastructure as code makes it auditable, reproducible, and version-controlled. -
📊 Observability baked-in
Metrics, tracing, and logging are first-class citizens — crucial for modern operations. -
🌍 Service discovery & dynamic routing
Smart traffic routing, retries, and load balancing out-of-the-box. -
🛡 Zero trust & least privilege are easier to implement
Policy-driven security reduces lateral movement risk. -
🔐 Secrets management integrated
Cloud-native stacks come with built-in support for secure credentials and rotation. -
🤹 Designed for failure and recovery
Self-healing via health checks, restarts, and rolling deployments is standard practice. -
🧰 Tooling ecosystem is mature and rapidly evolving
ECS, Kubernetes, Prometheus, ArgoCD, Envoy, and more — an explosion of powerful OSS tools. -
🔄 Easier hybrid and multi-cloud readiness
Apps built cloud-natively can move between on-prem, cloud, or edge with fewer changes. -
👥 Teams can operate independently
Microservices + GitOps allows autonomous delivery, faster iteration, and less coupling.
Cloud-Hosted (SaaS) Deployment
The most common deployment model is a cloud-hosted Software-as-a-Service (SaaS) offering, using AWS ECS on the AWS stack. This environment is designed for high availability, with infrastructure distributed across multiple AWS availability zones. The solution is fully PCI DSS Level 3 compliant, meeting stringent security and data protection standards.
In addition to the primary cloud offering, Eclipse is also deployed within EFT Corporation’s regional processing hubs across Africa to support regional compliance requirements while maintaining consistent operational standards.
Self Hosted Deployment
For institutions that require local control or must adhere to specific regulatory or data sovereignty requirements, Eclipse is also available as a self hosted deployment. This option allows Eclipse to be installed within the institution's own infrastructure or private cloud. For self hosted deployments AWS tooling is typically used along with ECS-Anywhere so that EFTCorp can manage the stack in a standardised familiar way with the same tooling for all management.
The specific architecture for a self hosted deployment is determined during a consultative process. This allows flexibility in how components such as TLS termination and load balancing are implemented — either through Eclipse's native tooling or by leveraging existing institutional infrastructure.
A standard architectural blueprint is described below, which has been successfully evaluated in prior PCI assessments and can be adapted to meet specific client environments.
This table summarises the roles and responsibilities with the hosted and self hosted deployment options:
| Area of Responsibility | Hosted (EFT Corporation) | Self-Hosted (Customer) |
|---|---|---|
| Infrastructure & Networking | EFT Corporation | Customer |
| Installation & Configuration | EFT Corporation | Shared: Customer - operating system & below EFT Corporation - applications & above |
| Upgrades & DevOps Support | EFT Corporation | Shared: Customer - operating system & below EFT Corporation - applications & above |
| PCI Compliance | EFT Corporation | Customer (with EFT Corporation technical support |
NoteAll self-hosted deployments are operated by EFT Corporation as a managed service, with associated commercial terms. For further information regarding licensing and operational costs, please contact EFTCorp directly.
Eclipse is essentially:
- MySQL 8 (latest sub version)
- A backend docker image that needs a MySQL database connection to pull all further configuration.
- A frontend docker image that runs NGINX and serves the Angular based portal.
Note: All persistent configuration — including tenant settings, permissions, wallet types, fee rules, and integration keys — is stored in MySQL. The container images are stateless. Replacing or scaling containers does not require any configuration migration.
The 2 docker images are provided to licensed customers by pushing to a private docker registry (typically ECR). Every time a production CI/CD build is run, the latest docker images are pushed to all customer registries. Customers can then choose to deploy following their own change control processes.
Within the Eclipse backend docker image, all Microservices are packaged together for ease of deployment and lower cost. There is however nothing stopping deployments from being broken up across Microservices but that is not within the scope of this installation guide.
MySQL Setup
The latest version of MySQL 8 is recommended. The MySQL system time must be UTC. The collation should be case-insensitive and use the utf8mb4 character set. As an example, to create a database schema called eclipse:
CREATE DATABASE eclipse
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_0900_ai_ci;After creating the schema, create a dedicated application user with full access to that schema. Eclipse should not connect as a MySQL administrator:
CREATE USER 'eclipse'@'%' IDENTIFIED BY 'strongpassword';
GRANT ALL PRIVILEGES ON eclipse.* TO 'eclipse'@'%';
FLUSH PRIVILEGES;Set the MySQL system timezone to UTC in my.cnf (or equivalent):
[mysqld]
default-time-zone = '+00:00'The exact setup of MySQL depends very much on the services used within Eclipse. As an example, if KYC/KYB functionality is being used, then document storage of passports etc takes up significant space and the database space requirements would need to compensate for this. If Eclipse is purely transactional data then the database is unlikely to exceed 1TB unless if traffic volumes are huge. An initial size of 800GB is recommended for the database virtual machines and would likely cover most scenarios for many years.
The one important choice is to always use SSD's for disks. Spinning disks are significantly slower and less reliable and should not be used. In a typical setup across 2 datacenters, a primary MySQL server would be used by both data centres, with a replica in the second data centre using standard MySQL master/slave replication. It is advised to use a SQL proxy, DNS entry with short TTL or a VIP to control the failover between the master and slave. This architecture depends on the implementation network configuration and capabilities. The simplest approach is a DNS entry for the primary DB endpoint that can be changed to point to the slave for failover.
Backend Setup
Multiple instances of the backend can run and they use Hazelcast to set up a cluster amongst themselves. The hazelcast configuration sits in property hazelcast.config and its recommended to use the Eclipse hazelcast discovery plugin in the config so that nodes can discover each other without the need for multicast:
<discovery-strategy enabled="true" class="com.ukheshe.arch.impl.hazelcast.discovery.UKDiscoveryStrategy">Refer to Hazelcast standard documentation for the setup of interfaces. A good starting point is:
<?xml version="1.0" encoding="UTF-8"?>
<hazelcast xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hazelcast.com/schema/config http://www.hazelcast.com/schema/config/hazelcast-config-5.3.xsd">
<cluster-name>SomeNameForYourCluster</cluster-name>
<map name="default">
<backup-count>1</backup-count>
<async-backup-count>1</async-backup-count>
</map>
<properties>
<property name="hazelcast.shutdownhook.enabled">false</property>
<property name="hazelcast.discovery.enabled">true</property>
<property name="hazelcast.heartbeat.failuredetector.type">deadline</property>
<property name="hazelcast.heartbeat.interval.seconds">5</property>
<property name="hazelcast.max.no.heartbeat.seconds">20</property>
</properties>
<network>
<interfaces enabled="true">
<interface>Site 1 subnet e.g. 10.20.21.*</interface>
<interface>Site 2 subnet e.g. 10.20.22.*</interface>
</interfaces>
<port auto-increment="false" port-count="1">5701</port>
<join>
<multicast enabled="false"/>
<tcp-ip enabled="false"/>
<discovery-strategies>
<discovery-strategy enabled="true" class="com.ukheshe.arch.impl.hazelcast.discovery.UKDiscoveryStrategy">
<properties>
</properties>
</discovery-strategy>
</discovery-strategies>
</join>
</network>
</hazelcast>The property table only exists after the initial boot so one can add the config after an initial boot. Always start Eclipse with one instance at first and then add additional instances once all the schema has been created and the system is operational.
The Eclipse docker image can be run in ECS, Kubernetes, Docker Swarm, Docker Compose, Plain Docker etc. The only requirement is that the following environment variables be passed into the container:
| ENV Parameter | Description | Example |
|---|---|---|
| MYSQLHOST | Hostname/IP and Port to connect to MySQL | 10.34.22.2:3306 |
| MYSQLUSER | Username for a MySQL user that has full access to the MYSQLSCHEMA. This parameter can optionally be populated with the ARN of an AWS secrets manager secret that has a JSON value with username and password e.g. {"username": "eclipse", "password": "1234567890"}. Eclipse should not connect using an administrator user but rather an application user. | eclipse or arn:aws:secretsmanager:eu-west-1:673586870961:secret:MySQLOdZimCredentials-1111111 |
| MYSQLPASS | Password of the MYSQLUSER. This parameter can optionally be populated with the ARN of an AWS secrets manager secret that has a JSON value with username and password e.g. {"username": "eclipse", "password": "1234567890"} | 1234567890 or arn:aws:secretsmanager:eu-west-1:673586870961:secret:MySQLOdZimCredentials-1111111 |
| MYSQLSCHEMA | Schema name (must exist) in MySQL that Eclipse will use | eclipse |
| UK_ENVIRONMENT | For production environments, make sure this starts with PROD and then a name. Set to DEVTEST for DEV or TEST environments | PROD_MYBANK |
| TLSLISTENPORT | If specified as an individual port (e.g. 8443) then a listener will be bound for TLS traffic on this port. If a range is provided (e.g. 8000-8009) then a random port in this range (inclusive) will be chosen that is currently not bound | 8000-8009 |
| ONLYTLS | Set to true to only use TLS (recommended) | true |
| CORS | If true, then Cross origin requests will be allowed from any domain. If false, they wont | true |
| JAEGERNAME | The service name prefix to use for Jaeger traces e.g. EclipseODZW | EclipseODZW |
| HEAPSETTINGSOVERRIDE | The JVM heap settings to use. Recommended to set this to -XmsZM -XmxZM where Z is the number of Megabytes for the Heap. Set Z to 60% of the containers allocated RAM. | -Xms2000M -Xmx2000M |
A typical Eclipse backend container should have 2 CPUs and 4 GB RAM. Set HEAPSETTINGSOVERRIDE to approximately 60% of the container RAM, e.g. -Xms2000M -Xmx2000M for a 4 GB container.
First Boot Sequence
- Start a single backend instance first. Do not start additional instances until the database schema has been fully created and the system is operational.
- Log in to the admin portal at
/admin-portalusing identitybootstrapwith any password. This bootstrap user is only active until the first real admin identity is created. - Create at least one
GLOBAL_ADMINidentity immediately after first boot. - Check the startup logs for warnings about default security keys — any default values flagged in the logs should be replaced with tenant-specific secrets before going live.
- Once the system is operational, start additional backend instances. They will auto-discover each other via Hazelcast using the
UKDiscoveryStrategyplugin.
The admin portal is available at https://<hostname>/admin-portal/ and calls the backend at https://<hostname>/eclipse-conductor/.
Frontend Setup
The frontend is a PWA with no state nor backend logic. Everything runs in the users browser. The Eclipse frontend docker image can be run in ECS, Kubernetes, Docker Swarm, Docker Compose, Plain Docker etc. The only requirement is that the following environment variables be passed into the container:
| ENV Parameter | Description | Example |
|---|---|---|
| LISTENPORT | If specified as an individual port (e.g. 9000) then a listener will be bound for http traffic on this port. If a range is provided (e.g. 9000-9009) then a random port in this range (inclusive) will be chosen that is currently not bound | 9000-9009 |
| BASEURL | The base path the frontend should look for. Generally, use /admin-portal | /admin-portal |
| DEBUG | Set to false | false |
The admin portal will call the Eclipse backend API on the same hostname as the portal, suffixed with /eclipse-conductor. The portal can run on a very small container - e.g. 1/4 CPU and 512MB RAM.
Standard Blueprint
Having understood that Eclipse is effectively 2 docker images and a MySQL database, the actual deployment architecture in a bank would be more complex due to network segmentation, failover, disaster recovery and the like. In a setup where the only available infrastructure is virtual machines in layer 3 network segments with firewalls, Eclipse should be deployed as follows:
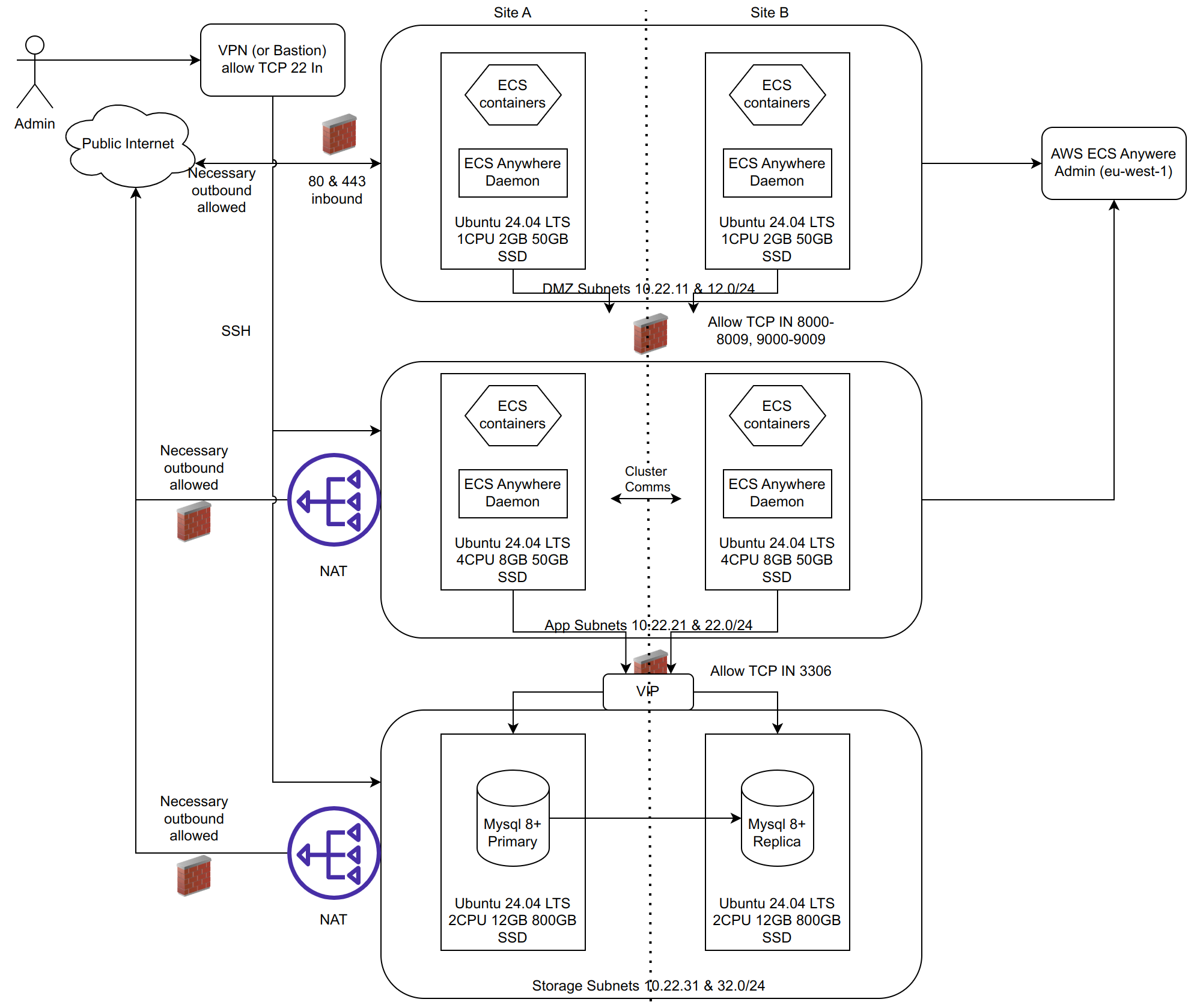
This provides for high availability across 2 sites less than 5ms apart from each other with the only single point of failure being the master MySQL database but with a replicated standby that can be failed over to with a MTTR of only a few minutes. MySQL is extremely stable and typically a failure of a database would be due to a hardware or network failure.
Capacity
The above standard deployment has 8 CPU's in the application layer. As a rule of thumb, Eclipse handles approximately 200tps per CPU. So this infrastructure would handle 1600tps. This is very dependent on the type of traffic and API calls and database disk speed. There is separate documentation on load test results available. Please contact EFTCorp directly if this is needed.
This table summarises the resource requirements for a base installation supporting 1600 tps.
| Layer | Purpose | Specifications |
|---|---|---|
| Layer 1 – Load Balancers | Traffic distribution & load balancing, 1 VM per site, stateless, horizontally scalable | 1 vCPU, 2 GB RAM, 50 GB SSD |
| Layer 2 – Application Servers | Core application components, 1 VM per site, stateless, horizontally scalable | 4 vCPU, 8 GB RAM, 50 GB SSD |
| Layer 3 – Data Storage | Persistent storage (MySQL 8), high I/O - 1 VM per site active standby deployment | 2 vCPU, 12 GB RAM, 800 GB SSD |
ECS Anywhere Daemon
The standard deployment blueprint utilises ECS Anywhere as an enterprise container orchestration and control plane allowing for a standardised PCI enabling operational environment while still running the services on-premise. This brings many of the benefits of cloud-native architectures without the nightmare of running ones own Kubernetes, identity management, centralised logging, Key Stores, Container registries and the like. If one is unfamiliar with ECS anywhere then the documentation is available at https://aws.amazon.com/ecs/anywhere/
A good overview of container orchestration can be found here: https://aws.amazon.com/what-is/container-orchestration/
In its simplest form, ECS Anywhere is a daemon that can be installed and run on Linux that makes that server appear in ones own AWS account as a ECS deployment target. So one can deploy and manage software on the server without needing to SSH in and do any manual upgrades and the like. Although it requires access to AWS for the control plane, if the access goes down, Eclipse continues to run. The following data is sent to EFTCorp for ongoing operations and maintenance:
- Desensitised system traces from Opentelemetry - used for troubleshooting and L3 support. Only stored for about a week
The following data is sent to the AWS cloud account (Account can be managed by EFTCorp or the bank). If it is a bank AWS account, then EFTCorp DevOps would need full access to cloudwatch and ECS.
- Desensitized logs
- System performance metrics (CPU utilisation, Heap sizes, thread pool activity, latencies, throughput etc)
Firewalling
Banks have strict firewalling policies but differ in the maturity and functionality of the network. Inbound access into subnets is very simple and restrictive firewall rules to open certain TCP ports as per the diagram. Oubound access is more complicated and depends on the services being offered by Eclipse. In days gone by, outbound access could be limited to certain static IP addresses but the advent of cloud services, CDN's and the like means that partner services typically have multiple IP addresses and can change over time and differ based on geo-location of the caller. Modern firewalls cater for this by supporting FQDN based outbound rules or the use of dynamic IP lists that are updated frequently. If this is available, then it can be used to limit outbound access on port 443 to partner services based on domains. If it is not available, then it is recommended to allow outbound access to port 443 on the internet or limit based on IP using heuristics but being aware that IP changes could cause service disruptions if partners add or change IP addresses. EFTCorp has not had any issues justifying the outbound access on port 433 to QSA's as part of PCI assessments.
The roles of the subnets are as follows:
Note subnet IP ranges are just examples and can be defined per deployment. For future proofing and scaling, subnets of /24 (254 possible hosts) are recommended
DMZ Subnets
The DMZ will have the following components deployed:
- HAProxy or equivalent HTTP load balancer and TLS termination. The load balancer is configured to balance across the portal and API backends with health checks to ensure traffic is only sent to healthy instances. When deployments happen, the load balancer ensures 100% uptime even during full redeployments.
- WAF - A software-based WAF to act as an initial L7 firewall to block common script jockey hacking attempts
The DMZ subnet would typically have inbound internet access for port 80 and 443 into load balancing virtual machines with public IP addresses to allow for certain functionality in Eclipse to be proxied to the internet. The exact use case of Eclipse would determine if the DMZ actually needs inbound access from the internet, or just from the banks private network. Inbound internet access would be needed if any of the following is needed:
- Eclipse API access from Apps and Web that consume the API's from the internet
- Card self-service directly by the end cardholder such as PIN setting and viewing card details where the caller of Eclipse API's is not PCI compliant and hence cannot have card data pass through them.
- Admin portal access from outside the banks network - this is recommended as it allows staff and support teams to support Eclipse from anywhere.
It is recommended that Eclipse is made available over the internet, as it is designed with this in mind. Its security, encryption and authentication models have all been built with the knowledge that it would likely be open to the internet. This is not seen as a risk and is PCI compliant as all necessary precautions are catered for with firewalling, WAF and the functionality of the Eclipse conductor for XSS detection, brute force etc. Having said this, inbound access can be limited to just a banks private network but this would limit the use cases of Eclipse being used as an API-first digital banking platform or at least mean that all API's would need to be consumed by another layer in the bank which in turn is open to the internet itself (e.g. a banking channel like internet banking backend).
Outbound access from the DMZ would depend on how package management, OS updates and the like are done. Outbound access from this layer to the internet via a NAT gateway is not seen as a risk. At an absolute minimum, the ECS anywhere daemon should be able to access AWS for container orchestration, metrics, logs and the like. For this to function, outbound TLS access to port 443 on all *.eu-west-1.amazonaws.com should be allowed.
App Subnets
These contain the actual Eclipse backend and portal docker containers. They only have private IP addresses. They store no state on disk at all. They would be accessible only to the HAProxy/WAF in the DMZ. Typically, the backend microservices containers would listen on TLS on ports 8000-8009 while the containers for the portals would listen on ports 9000-9009.
The App subnets should have access between them (e.g. across 2 datacenters) so that they can share cluster state. This should not exceed 5ms latency. If the latency exceeds 5ms then it is recommended to run in Active/Active in a single datacenter with a DR datacenter in cold standby.
Outbound internet access from the App subnet depends on use cases for Eclipse. If Eclipse needs to communicate with third parties (VISA API's, Mastercard API's, Card manufacturer FTP servers, Document OCR, Azure passport validation, SMS gateways, ACS providers, Email servers etc etc) then this access would need to be opened. Its is recommended to open outbound access to the internet on port 443 and then add additional ports based on need (e.g. for FTP, SMTP, Tracing etc). As with the DMZ, for keys, secrets, logs, metrics and container orchestration, outbound TLS access to port 443 on all *.eu-west-1.amazonaws.com should be allowed.
Storage Subnets
The storage subnet is the most secure and is where all persisted/state data lies. They only have private IP addresses. This layer need only allow MYSQL traffic in on port 3306. Outbound access is only needed for container updates, deployments, OS updates etc. These are typically outbound on port 443 and can be opened during change controls where DB updates are needed or OS updates and patching are needed. One should not be tempted to change the MySQL port from 3306 to some other port. Use of non-standard port numbers is not considered a security precaution but more a hinderance to operations and maintenance. The risk of someone opening access to an unfamiliar port like 7700 is far greater than an adminstrator seeing port 3306 and knowing this is most likely MySQL and hence to be treated with caution.
Backups
The DMZ and App subnets dont store any state but can be backed up using the virtualisation snapshot technology preferred by the bank. Any state or data that happens to be on those servers is considered ephemeral.
Daily backups of the database would be scheduled as part of the installation process and would require a location to place these backups. The bank can ship backups from this location and store and age them as per their own policies. If the bank has specific backup technology in use then this can be accommodated but ultimatel,y the testing and implementation of these mechanisms would be up to the bank. MySQL itself can be restored so long as the backup file is restored onto a server.
General Configuration
All possible configuration is stored in the database. The only configuration that is passed into the system when it starts are the environment parameters referenced earlier in this document. This simplifies deployments and setup considerably.
Access to Virtual Machines
EFTCorp would need SSH access to the virtual machines with a user capable of sudo for initial deployment and then for any administration tasks or third level support. The means of access can be determined by the bank (VPN, Jumpbox etc).
Virtual Machine Operating System
EFTCorp has extensive experience with Ubuntu and would recommend the latest LTS version available. It is proven to work well with ECS Anywhere and "just works". Some banks prefer to use RHEL but the experience has been less favourable, requiring some manual IPTables changes and generally less reliable agent connectivity. If RHEL is needed then version 9.5 can be used but the recommendation remains to use Ubuntu 24.04 LTS
RabbitMQ (Event Bus)
Eclipse uses RabbitMQ for internal event publishing between microservices (e.g. wallet credit/debit events, KYC completion, card status changes). In the standard single-image deployment, RabbitMQ runs embedded. For high-availability multi-node deployments, an external RabbitMQ cluster can be configured. Contact EFTCorp for guidance on externalised RabbitMQ configuration for your deployment scale.
Environment Benchmarking
Eclipse has a built-in benchmark that will run a load test with a configurable number of threads (parallelism) for a specific duration against each node in the cluster simultaneously. The benchmark can be called as an API as follows:
curl 'https://<hostname>/eclipse-conductor/rest/v1/global/benchmark?duration=20&threads=30' -H "Authorization: $BEARER"The BEARER token should be a JWT of someone with GLOBAL or INSTITUTION ADMIN permissions. The benchmark will run for approximately the number of seconds passed in the duration parameter. Threads should generally be set to 15 times the number of CPU's each node in the cluster has. Only run one test at a time! The results are an array (one entry per node in the cluster) in the format:
[{"tps":448,"tpsPerProcessor":224,"averageLatencyMs":66.683,"errors":0,"success":9045,"incomplete":0,"hostName":"ip-172-31-43-71.eu-west-1.compute.internal","jvmId":"61ebd687-0161-495a-be78-b20ae7e0233e","processorCount":2},{"tps":422,"tpsPerProcessor":211,"averageLatencyMs":70.693,"errors":0,"success":8537,"incomplete":0,"hostName":"ip-172-31-39-223.eu-west-1.compute.internal","jvmId":"d56c2a1f-b691-4d2b-b94c-57dd73f6490f","processorCount":2},{"tps":418,"tpsPerProcessor":209,"averageLatencyMs":71.356,"errors":0,"success":8459,"incomplete":0,"hostName":"ip-172-31-36-87.eu-west-1.compute.internal","jvmId":"5b2ff954-32c6-477d-8243-f6b5a03fcb08","processorCount":2},{"tps":422,"tpsPerProcessor":211,"averageLatencyMs":70.800,"errors":0,"success":8606,"incomplete":0,"hostName":"ip-172-31-37-217.eu-west-1.compute.internal","jvmId":"78564860-38bd-4155-89ba-07c5dc3f7d7e","processorCount":2}]tps: The number of transactions per second on the node achieved during the benchmark
tpsPerProcessor: The number of transactions per second per cpu achieved on the node
averageLatencyMs: Average ms per transaction
errors: Number of transaction errors in the test (should be 0)
success: Number of successful transactions
incomplete: Number of transactions that got no response by the time the test ended (should be 0)
hostName: hostname of the node
jvmId: JVM identifier in the cluster
processorCount: number of processors the node has available
Each transaction processed consists of:
- An HTTPS call to a microservice (load balanced randomly across members in the cluster) that:
- POSTS about 1kB random bytes of data in JSON
- The microservice deserialises the JSON, writes and commits and reads the row in the database of approximately 1kB
- Returns 1kB random bytes of data in JSON
- An HTTPS call to a microservice (load balanced randomly across members in the cluster) that:
- Does a GET for the row previously written
- The microservice reads the row (indexed) and serialises it to JSON
- Returns the serialised bytes of data in JSON
So in short, a transaction consists of 2 microservice calls (1 write and then 1 read). The data size is a typical size of a large API call and large database write and 2 reads.
Tests across various environments shows that benchmark gives a good indication of what the environment is capable of processing at peak (e.g. card transactions per second or wallet transfers per second). On typical hardware with a sufficiently scaled database, one should be able to achieve approximately 200 tps per CPU core in the application layer of the environment. E.g. in the blueprint environment with 2 servers and 2 CPU used for App layer docker containers per server, thats 4 CPUs (cores) and hence approximately 800tps. This would be at 100% CPU utilisation and is not sustainable for long periods. Once should scale an environment for about max 50% CPU utilisation at peak volumes.
Due to JVM hotspot compilation and connecion pool growth, run a number of benchmarks until a stable result is achieved.
If performance does not align to this, investigations should be done to understand where the bottleneck lies by analysing CPU utilisation and Database disk IO/wait times and network latency between the application servers and database. It is extremely unlikely that any performance issues are related to the code itself as this is tested on many environments before being certified for release.